../how-to-build-your-own-jvm-2
如何构建你自己的 JVM (1) 解释器
Published:
种一棵树最好的时间是十年前, 其次是现在.
0x00 几点概念
解释器
解释器, 是一种程序,能够把编程语言一行一行解释运行。解释器像是一位“中间人”,每次运行程序时都要先转成另一种语言再作运行,因此解释器的程序运行速度比较缓慢。它不会一次把整个程序翻译出来,而是每翻译一行程序叙述就立刻运行,然后再翻译下一行,再运行,如此不停地进行下去。
指令
一些相关的概念, 汇编指令, JVM 字节码指令.
指令一般很简单, 描述了一个具体的操作. 比如
汇编指令
mov &ex, 1 => 将整数 1 放到寄存器 ex 里.
字节码指令
bpush 1 => 将 byte 1 放到操作数栈顶.
寄存器
寄存器, 简单来说寄存器就是个 Map. 可以根据寄存器地址(key)对其进行存取(value). 主要操作 get(key) , put(key,value)
栈
简单来讲, 后进先出, 只支持 push 和 pop 操作.
push : 将某个值放到栈的栈顶, 栈大小加 1.
pop : 将栈的栈顶的值弄出来, 栈大小减 1.
局部变量表
栈帧内部的数据结构, 是个数组. 通过数组位置访问, e.g array[0], array[1]. 换个角度来看, 其实可以认为是个特殊的寄存器. 只不过 key 是下标而已.
操作数栈
栈帧内部数据结构, 同栈.
0x01 寄存器还是栈
脱离业务场景的技术设计都是耍流氓. -- 尼古拉斯.赵四
场景
伪代码如下.
int a = 1 + 1;
int b = 2 + 2;
int c = 0;
int d = b - a;
int d = d - c;
println(d)
如果正确运行, 必然输出 2.
自动化的前提是能手动化. 所以人肉编译一下吧.
寄存器方案
生成指令格式, inst [value|address]+
e.g
mov &0 1 => 把数值 1 放到寄存器 0 里
add &3 &0 &1 &2 => 把 寄存器 0 ,寄存器 1, 寄存器 2 里的值相加, 并把结果放到 寄存器 3 里.
sub &3 &0 &1 &2 => 把 寄存器 0 里的值 减去 寄存器 1, 寄存器 2 里的值, 并把结果放到 寄存器 3 里.
println &3 => 取出 寄存器 3 的值 并输出.
生成的指令代码如下. 为方便理解, 双斜杠之后为注释. 表明操作之后寄存器或栈的状态
mov &0 1 // {0:1}
mov &1 1 // {0:1, 1:1}
add &2 &0 &1 // {0:1, 1:1, 2:2}
mov &3 2 // {0:1, 1:1, 2:2, 3:2}
mov &4 2 // {0:1, 1:1, 2:2, 3:2, 4:2}
add &5 &3 &4 // {0:1, 1:1, 2:2, 3:2, 4:2, 5:4}
mov &6 0 // {0:1, 1:1, 2:2, 3:2, 4:2, 5:4, 6:0}
sub &7 &5 &2 // {0:1, 1:1, 2:2, 3:2, 4:2, 5:4, 6:0, 7:2}
sub &8 &7 &6 // {0:1, 1:1, 2:2, 3:2, 4:2, 5:4, 6:0, 7:2, 8:2}
println &8 // {0:1, 1:1, 2:2, 3:2, 4:2, 5:4, 6:0, 7:2, 8:2}
栈方案
生成指令格式 inst [value]{0,1}
e.g
push 1 => 将数值 1 推到栈顶. (..) -> (..,1)
add => 将栈顶的两个数值相加, 并将结果放到栈顶. (..,v1,v2) -> (..,v1+v2)
sub => 假设栈顶值为v2, (..,v1,v2) -> (..,v1-v2)
swap => 交换栈顶两个元素 (v1,v2) -> (v2,v1)
swap1 => 交换栈上第二,第三位置 (v1,v2,x) -> (v2,v1,x)
println => 栈顶数值出站, 并将结果输出. (..,1) -> (..)
生成的指令代码如下. 为方便理解, 双斜杠之后为注释. 表明操作之后寄存器或栈的状态
push 1 // (1)
push 1 // (1, 1)
add // (2)
push 2 // (2, 2)
push 2 // (2, 2, 2)
add // (2, 4)
push 0 // (2, 4, 0)
swap // (2, 0, 4)
swap1 // (0, 2, 4)
swap // (0, 4, 2)
sub // (0, 2)
swap // (2, 0)
sub // (2)
println // ()
混合方案, 结合寄存器和栈的方案(即 JVM 的方案)
e.g:
load => 从寄存器中取值并 push 到操作数栈中.
store => 操作数栈顶数值出栈, 并存放到寄存器中.
生成的指令代码如下. 为方便理解, 双斜杠之后为注释. 表明操作之后寄存器或栈的状态
push 1 // (1) {}
push 1 // (1, 1) {}
add // (2) {}
store &0 // () {0:2}
push 2 // (2) {0:2}
push 2 // (2, 2) {0:2}
add // (4) {0:2}
store &1 // () {0:2, 1:4}
push 0 // (0) {0:2, 1:4}
store &2 // () {0:2, 1:4, 2:0}
load &1 // (4) {0:2, 1:4, 2:0}
load &0 // (4, 2) {0:2, 1:4, 2:0}
sub // (2) {0:2, 1:4, 2:0}
store &3 // () {0:2, 1:4, 2:0, 3:2}
load &3 // (2) {0:2, 1:4, 2:2, 3:2}
load &2 // (2, 0) {0:2, 1:4, 2:2, 3:2}
sub // (2) {0:2, 1:4, 2:2, 3:2}
store $4 // () {0:2, 1:4, 2:2, 3:2, 4:2}
load $4 // (2) {0:2, 1:4, 2:2, 3:2, 4:2}
println // () {0:2, 1:4, 2:2, 3:2, 4:2}
简单比较
简单场景下, 三种方案均可满足需求.
其中寄存器方案对应这计算机物理实现. CPU 的处理便是基于寄存器的. 优点性能高, 数据的搬运次数少, 缺点指令复杂.
纯粹基于栈的方案, 貌似没有, 因为只有 push pop 两种操作, 在局部变量较多的情况下, 数据需要频繁搬运. 优点是指令简单. 方便移植.
混合方案, 集两家之长, 在移植性和效率上的折中方案.
0x02 解释器核心
如上篇预告. 解释器的核心是一个循环.
do {
获取下一个指令
解释指令
} while (还有指令);
架构图如下
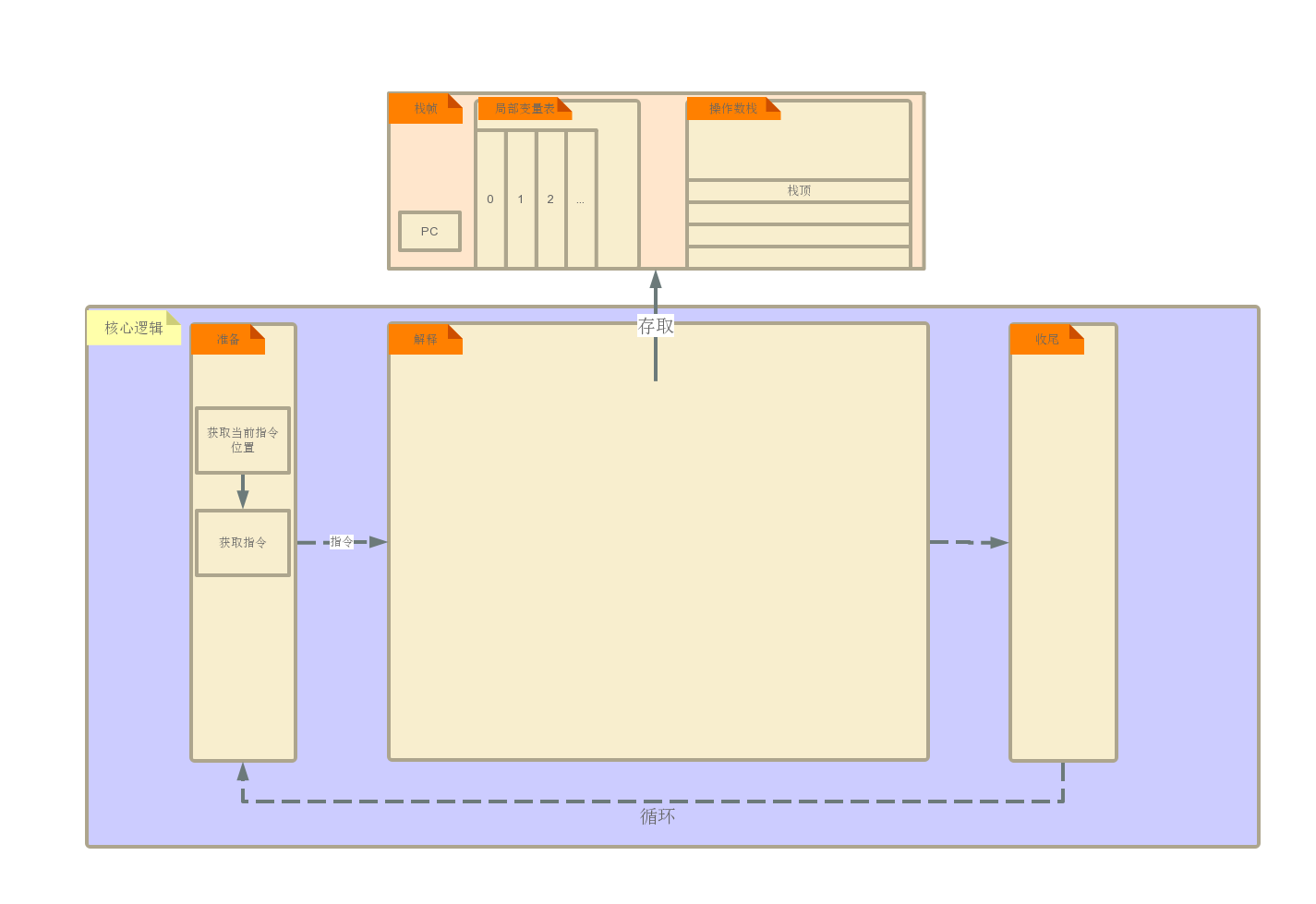
0x03 简单代码实现
寄存器
// 核心循环
public void run() {
List<Inst> insts = genInsts();
int size = insts.size();
int pc = 0;
while (pc < size) {
Inst inst = insts.get(pc);
inst.execute();
pc++;
}
}
// Add 指令实现
class AddInst implements Inst {
public final Integer targetAddress;
public final Integer[] sourceAddresses;
AddInst(Integer targetAddress, Integer... sourceAddresses) {
this.targetAddress = targetAddress;
this.sourceAddresses = sourceAddresses;
}
@Override
public void execute() {
int sum = 0;
for (Integer sourceAddress : sourceAddresses) {
sum += RegisterDemo.REGISTER.get(sourceAddress);
}
RegisterDemo.REGISTER.put(targetAddress, sum);
}
}
代码地址: 寄存器 DEMO
栈
// 核心循环
public void run() {
List<Inst> insts = genInsts();
int size = insts.size();
int pc = 0;
while (pc < size) {
Inst inst = insts.get(pc);
inst.execute();
pc++;
}
}
// Add 指令实现
class AddInst implements Inst {
@Override
public void execute() {
Integer v2 = StackDemo.STACK.pop();
Integer v1 = StackDemo.STACK.pop();
StackDemo.STACK.push(v1 + v2);
}
}
地址: 栈 DEMO
混合
// 核心循环
public void run() {
List<Inst> insts = genInsts();
int size = insts.size();
int pc = 0;
while (pc < size) {
Inst inst = insts.get(pc);
inst.execute();
pc++;
}
}
// Add 指令实现
class AddInst implements Inst {
@Override
public void execute() {
Integer v2 = HybridDemo.STACK.pop();
Integer v1 = HybridDemo.STACK.pop();
HybridDemo.STACK.push(v1 + v2);
}
}
地址: 混合 DEMO
关于上方代码
针对具体场景实现, 刚好能用. 三个方案, 每个方案均不超过 100 行代码. 回上篇问题, 实现一个简单的解释器, 10 分钟够不够?
自然是够的, 有兴趣不妨试着写一下.
0x04 小结
本文讨论了解释器实现的三种方案, 并就简单的案例分别实现了相应的解释器.
mini-jvm 便是从这简单的核心中慢慢扩展而来.
由于 JVM 选择的是混合方案, 后续的重点就只会在混合方案上了.
!!! 解释器的核心实现尤为重要, 如果此文并没有并没有让读者理解, 一定是文章的问题, 欢迎提出你的问题, 已迭代此文.
0x05 预告
- 当前的解释器跟 javac 编译之后的 class 一毛钱的关系都没有, 该有点关系了.
0x06 FAQ
- 为什么先从解释器说起, 按照惯例, 不应该先说说 classfile 解析吗? Classfile 解析并无任何难度, 体力活, 解析完的数据是为解释器服务的. 本质上是个静态数据提供者. 非核心逻辑. 故而解释器在前.